AI Breakthrough: Poetiq’s Meta-System Boosts Coding Accuracy Without Touching Model Internals, Automatic Harness Breaks SOTA on LiveCodeBench Pro
San Francisco, CA — Poetiq has achieved a major milestone in AI coding: its Meta-System automatically built and optimized a model-agnostic inference harness that improved every large language model (LLM) tested on the competitive LiveCodeBench Pro (LCB Pro) benchmark — all without any fine-tuning or internal access to the models.
The headline numbers: GPT 5.5 High, paired with Poetiq’s harness, scored 93.9% on LCB Pro (25Q2), up from a baseline of 89.6%. Meanwhile, Gemini 3.1 Pro — the model the harness was specifically optimized on — jumped from 78.6% to 90.9%, surpassing Google’s own Gemini 3 Deep Think (88.8%), a model that is not even available via API for independent verification.
“This is the first time a system has demonstrated that a purely external harness — built automatically and without touching model weights — can deliver such consistent gains across multiple frontier models,” said a Poetiq spokesperson in a statement. “The Meta-System recursively improves its own construction process, and the resulting harness works out-of-the-box on any LLM.”
Background
LiveCodeBench Pro is a demanding coding benchmark that resists data contamination and overfitting. Problems are drawn from competitive programming contests, and ground-truth code is withheld. Solutions are validated against strict memory and runtime constraints, and the problem set is continuously updated.
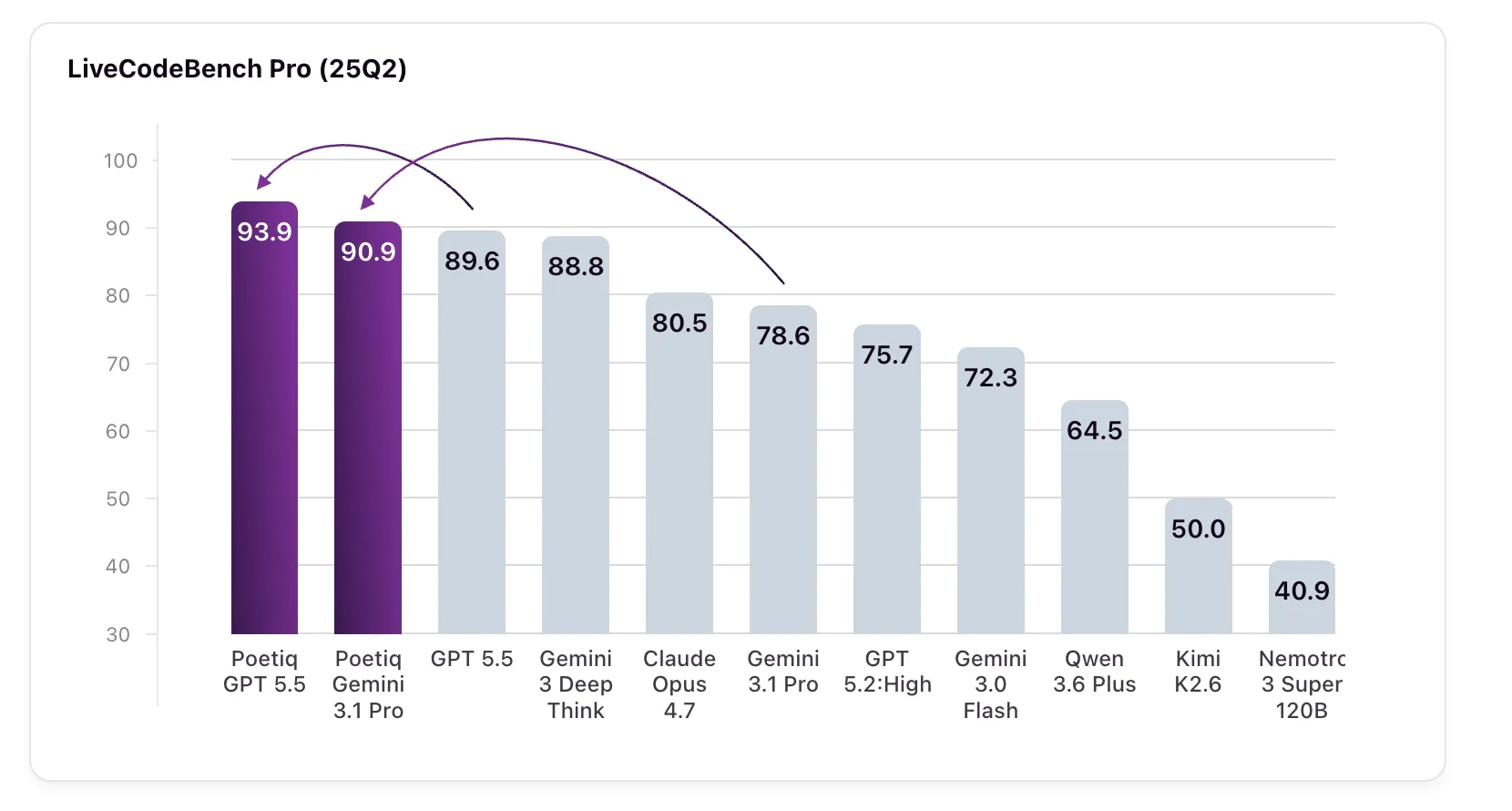
The benchmark focuses on C++ challenges that require creative, performant procedural logic — not just tool use or bug fixing. Poetiq chose LCB Pro deliberately to test three objectives: proving that an intelligent harness can boost performance without fine-tuning; validating the Meta-System’s ability to recursively self-improve while building the harness; and confirming that the resulting harness is fully model-agnostic. According to the company, all three objectives were met.
What Is a Harness?
A harness, in this context, is the infrastructure layer that wraps an LLM during inference — handling prompt construction, output parsing, error recovery, and iterative refinement. Poetiq’s Meta-System generates this harness automatically, optimizing it for the target benchmark without needing access to model internals.

“Think of the harness as a smart scaffold that helps the model reason more effectively about code,” explained Dr. Lena Tran, an independent AI researcher not involved in the study. “Poetiq’s approach shows that you can get significant gains purely by improving that scaffold, rather than retraining the model itself.”
What This Means
The implications are far-reaching. If harnesses can be automatically generated and optimized for any LLM, organizations could boost performance on specialized tasks without expensive fine-tuning or proprietary model access. This could democratize access to state-of-the-art coding AI, especially for smaller teams.
“This approach challenges the assumption that the best way to improve model performance is to tweak the model itself,” said Poetiq’s spokesperson. “Our results suggest that the inference harness is a previously under-explored lever — and that an automated Meta-System can find improvements no human engineer would have guessed.”
However, experts caution that the harness was optimized on a single benchmark. “We need to see whether these gains transfer to other coding tasks or real-world software engineering,” warned Dr. Tran. “But the methodology is sound, and the consistency across models is remarkable.”
Poetiq plans to release the harness and Meta-System details in a forthcoming paper, enabling independent replication. The company also intends to apply the same technique to reasoning (ARC-AGI) and retrieval (Humanity’s Last Exam) benchmarks, where they have already reported initial success.
This is a developing story. Check back for updates.
Related Articles
- Testing Code When You Don't Know Its Internals: A New Approach for AI-Driven Development
- Mastering Claude Opus 4.7 on Amazon Bedrock: A Complete Deployment Guide
- Gemma 4 Arrives on Docker Hub: Lightweight AI Models for Every Workload
- Deep Dive: Live updates from Elon Musk and Sam Altman’s court battle over t...
- Testing the Unknown: Strategies for AI-Generated Code
- 7 Surprising Facts About ChatGPT's 'Strawberry' Breakthrough and Its Persistent Flaws
- Mastering Pydantic AI: A Comprehensive Guide to Type-Safe LLM Agents
- What You Need to Know About Elon Musk confirms xAI used OpenAI’s models to ...